Elementos de redes neuronales#
Este ensayo está inspirado en micrograd de Andrej Karpathy, así como su texto sobre redes neuronales [Karpathy, circa 2014]. A continuación, construiremos una red neuronal desde cero, explicando a detalle cada uno de sus elementos.
La derivada demostrada según el orden geométrico#
Las redes neuronales son gigantescas funciones matemáticas. La característica distintiva de estas funciones, que catalizan gran parte de lo que hoy se denomina «inteligencia artificial» (aunque, más estrictamente, deberíamos hablar de «aprendizaje profundo» o deep learning), es que pueden «aprender» a refinar, optimizar y generalizar las «reglas» (parámetros) que las componen. Tal proceso de aprendizaje consiste en la iteración de operaciones matemáticas propias del cálculo diferencial y vectorial. Por ello, para poder formular una red neuronal, procuraremos primero entender intuitivamente a la derivada: esa médula matemática del aprendizaje.
Para tal propósito, construiremos la derivada desde cero, utilizando apenas unas cuantas nociones básicas de geometría.
En geometría, denominamos «pendiente» al valor de la inclinación de una recta. Conceptualmente, la pendiente puede ser interpretada como la proporción del cambio que hay entre las variables
!pip install matplotlib --upgrade
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
x = np.arange(0, 21, 2)
b = 5
def f(x, b): return x*b
y = f(x, b)
d = {'Valores de x': x, 'Valores de b': b, 'Valores de y': y}
tabla = pd.DataFrame(data=d)
tabla = tabla.style.hide_index()
tabla
| Valores de x | Valores de b | Valores de y |
|---|---|---|
| 0 | 5 | 0 |
| 2 | 5 | 10 |
| 4 | 5 | 20 |
| 6 | 5 | 30 |
| 8 | 5 | 40 |
| 10 | 5 | 50 |
| 12 | 5 | 60 |
| 14 | 5 | 70 |
| 16 | 5 | 80 |
| 18 | 5 | 90 |
| 20 | 5 | 100 |
En términos más simples, la función es una multiplicación entre
fig, ax = plt.subplots(figsize=(10, 7))
ax.plot(x, y, marker='o', color='blue')
plt.xticks(ticks=x)
plt.yticks(ticks=y)
ax.set_facecolor('black')
ax.set_xlabel('Valores de x')
ax.set_ylabel('Valores de y')
ax.hlines(y=10, xmin=0, xmax=2, linewidth=1, color='white', linestyles='dashed')
ax.vlines(x=2, ymin=0, ymax=10, linewidth=1, color='white', linestyles='dashed')
plt.show()
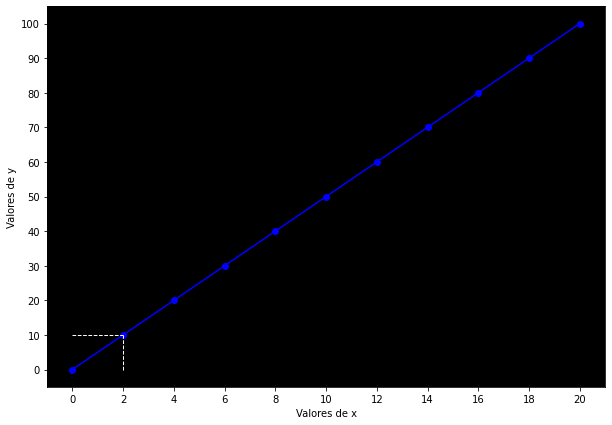
Ahora, ¿cómo puedo saber cuánto está influyendo cada valor de
En ese sentido, la proporción que hay entre
La fórmula de la pendiente nos ofrece un método general para calcular esta proporción o fuerza de la que hablamos:
Entonces la fórmula solo nos dice que debemos tomar dos puntos cualesquiera de
Pero las funciones lineales —es decir, las rectas—, por definición tienen la misma inclinación en todos sus puntos o segmentos. Comprobémoslo cambiando nuestras
Naturalmente, la pendiente sigue siendo la misma. Ahora reiteremos, ¿exactamente qué quiere decir el número cinco? Que por cada paso que damos en
Visualicemos la pendiente en color rojo:
pendiente = (y[6] - y[3]) / (x[6] - x[3])
print(f'Valor de la pendiente: {pendiente}')
fig, ax = plt.subplots(figsize=(10, 7))
ax.plot(x, y, marker='o', color='blue', label='recta de la función')
plt.xticks(ticks=x)
ax.set_facecolor('black')
ax.set_xlabel('Valores de x')
ax.set_ylabel('Valores de y')
ax.axline((x[6], y[6]), slope=pendiente, color='red', label='pendiente')
ax.hlines(y=10, xmin=0, xmax=2, linewidth=1, color='white', linestyles='dashed')
ax.vlines(x=2, ymin=0, ymax=10, linewidth=1, color='white', linestyles='dashed')
ax.legend()
plt.show()
Valor de la pendiente: 5.0
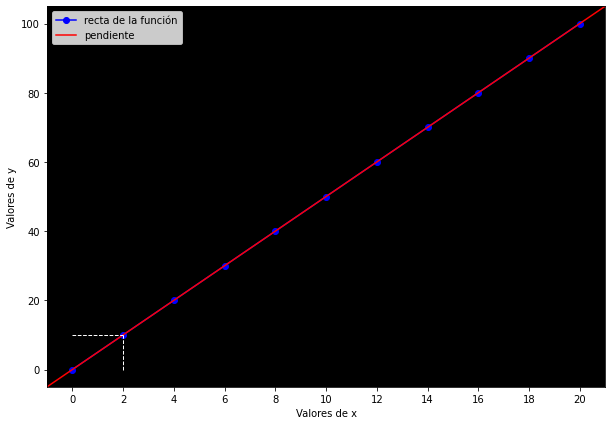
La pendiente es idéntica a la recta porque, como decíamos, la recta tiene la misma inclinación —pendiente— en todos sus puntos. Ahora, el problema con la pendiente es que esta propiedad es al mismo tiempo una limitación fundamental: la pendiente solo es válida para una recta o función lineal.
Dado que las funciones no lineales no tienen la misma inclinación en todos sus puntos, no podemos hablar de la «inclinación» ni de la «pendiente de una función no lineal». Visualicémoslo con una función cuadrática, donde mis valores de
x = np.arange(0, 6, 0.0001)
def nolineal(x): return x**2
y = nolineal(x)
pendiente = (5**2 - 2**2) / (5 - 2)
fig, ax = plt.subplots(figsize=(10, 7))
ax.plot(x, y, color='blue', label='gráfica de la función')
ax.set_facecolor('black')
ax.set_xticks(np.arange(-5, 6, 1))
ax.set_xlabel('Valores de x')
ax.set_ylabel('Valores de y')
ax.set_ylim(min(y), max(y))
ax.set_xlim(min(x), max(x))
ax.axline((2, 4), slope=pendiente, color='red', label='pendiente?')
ax.hlines(y=4, xmin=0, xmax=2, linewidth=1, color='white', linestyles='dashed')
ax.hlines(y=25, xmin=0, xmax=5, linewidth=1, color='white', linestyles='dashed')
ax.vlines(x=2, ymin=0, ymax=4, linewidth=1, color='white', linestyles='dashed')
ax.vlines(x=5, ymin=0, ymax=25, linewidth=1, color='white', linestyles='dashed')
ax.legend()
plt.show()
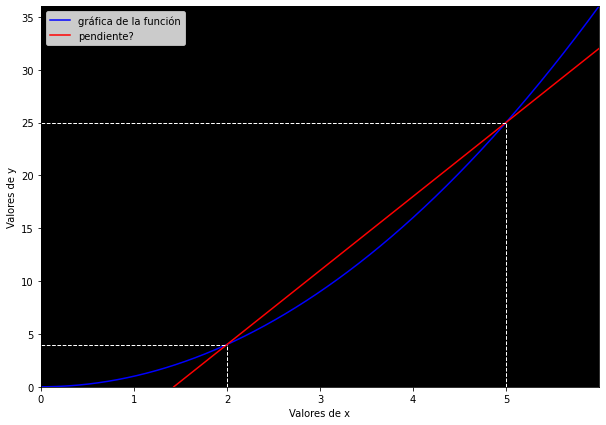
Para calcular la inclinación de la función (es decir, la curva azul) cuando
Pero la realidad es que mi función no cambió en esa proporción con respecto al punto
Además de que la función tiene múltiples «pendientes» —porque su inclinación siempre cambia—, estas «pendientes» son inexactas, puesto que no miden con precisión el impacto (o inclinación) de un solo punto en la función, sino que la fórmula de la pendiente necesariamente nos ofrece la inclinación de una recta trazada entre dos valores de
Entonces, ¿cómo puedo hacer para encontrar el verdadero impacto de
pendiente = (5**2 - 4**2) / (5 - 4)
print(f'Valor de la pendiente con una secante más pequeña: {pendiente}')
fig, ax = plt.subplots(ncols=2, figsize=(10, 7))
ax[0].plot(x, y, color='blue', label='gráfica de la función')
ax[0].set_facecolor('black')
ax[0].set_xticks(np.arange(0, 6, 1))
ax[0].set_xlabel('Valores de x')
ax[0].set_ylabel('Valores de y / f(x)')
ax[0].axline((5, 25), slope=pendiente, color='red', label='pendiente?')
ax[0].hlines(y=16, xmin=0, xmax=4, linewidth=1, color='white', linestyles='dashed')
ax[0].hlines(y=25, xmin=0, xmax=5, linewidth=1, color='white', linestyles='dashed')
ax[0].vlines(x=4, ymin=0, ymax=16, linewidth=1, color='white', linestyles='dashed')
ax[0].vlines(x=5, ymin=0, ymax=25, linewidth=1, color='white', linestyles='dashed')
ax[0].legend()
ax[1].plot(x, y, color='blue', label='gráfica de la función')
ax[1].set_facecolor('black')
ax[1].set_xticks(np.arange(-5, 6, 1))
ax[1].set_xlabel('Valores de x')
ax[1].set_ylabel('Valores de y / f(x)')
ax[1].set_title('Zoom')
ax[1].set_ylim(12, 30)
ax[1].set_xlim(2, 7)
ax[1].axline((5, 25), slope=pendiente, color='red', label='pendiente?')
ax[1].hlines(y=16, xmin=0, xmax=4, linewidth=1, color='white', linestyles='dashed')
ax[1].hlines(y=25, xmin=0, xmax=5, linewidth=1, color='white', linestyles='dashed')
ax[1].vlines(x=4, ymin=0, ymax=16, linewidth=1, color='white', linestyles='dashed')
ax[1].vlines(x=5, ymin=0, ymax=25, linewidth=1, color='white', linestyles='dashed')
ax[1].legend()
plt.show()
Valor de la pendiente con una secante más pequeña: 9.0
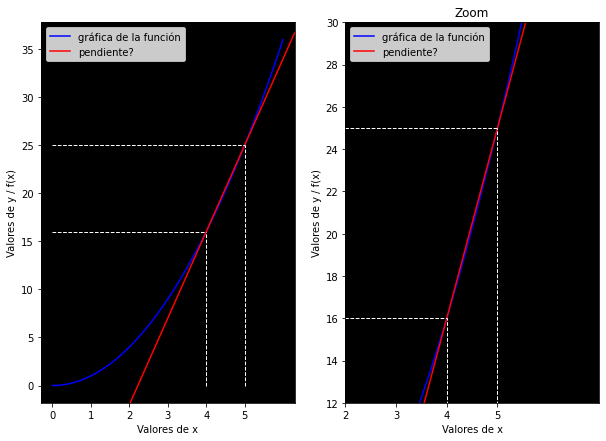
Gráficamente podemos comprobar que hemos obtenido un mucho mejor resultado: la secante que trazamos tiene una inclinación similar a la de la curva de la función. Pero las líneas punteadas —las cuales denotan los puntos que hemos tomado como referencia para calcular la pendiente— nos indican que todavía podemos mejorar, tomando como referencia coordenadas más cercanas entre sí.
Bien, pues antes de continuar experimentando, adelantemos ya que esta línea de razonamiento es precisamente la que dio origen a la derivada. El truco es este: podemos calcular la pendiente de líneas secantes cada vez más pequeñas y similares a nuestro punto, obteniendo cada vez mejores resultados. Es más, podemos llegar a calcular la pendiente de una línea infinitamente pequeña, tan pequeña que sería casi idéntica al punto, y la pendiente de esa línea infinitamente pequeña sería igual a la pendiente del punto. En ese mismo sentido, podríamos decir incluso —y de hecho se hace así en el ámbito matemático— que estamos calculando la pendiente de una línea tangente al punto, puesto que su pendiente sería igual a la de una secante infinitamente pequeña que se confunde con el punto.

Fig. 2 Como en la imagen, queremos obtener la pendiente de una secante cada vez más pequeña —más cercana al punto que nos interesa—, es decir, con una distancia
Utilizando la fórmula de la pendiente para poner en práctica nuestra intuición, podemos conseguir un resultado como este:
pendiente = (5**2 - 4.99**2) / (5 - 4.99)
print(f'Valor de la pendiente con una secante más pequeña: {pendiente}')
fig, ax = plt.subplots(ncols=2, figsize=(10, 7))
ax[0].plot(x, y, color='blue', label='gráfica de la función')
ax[0].set_facecolor('black')
ax[0].set_xticks(np.arange(0, 6, 1))
ax[0].set_xlabel('Valores de x')
ax[0].set_ylabel('Valores de y / f(x)')
ax[0].axline((5, 25), slope=pendiente, color='red', label='pendiente?')
ax[0].hlines(y=4.99**2, xmin=0, xmax=4.99, linewidth=1, color='white', linestyles='dashed')
ax[0].hlines(y=25, xmin=0, xmax=5, linewidth=1, color='white', linestyles='dashed')
ax[0].vlines(x=4.99, ymin=0, ymax=4.99**2, linewidth=1, color='white', linestyles='dashed')
ax[0].vlines(x=5, ymin=0, ymax=25, linewidth=1, color='white', linestyles='dashed')
ax[0].legend()
ax[1].plot(x, y, color='blue', label='gráfica de la función')
ax[1].set_facecolor('black')
ax[1].set_xticks(np.arange(-5, 6, 1))
ax[1].set_xlabel('Valores de x')
ax[1].set_ylabel('Valores de y / f(x)')
ax[1].set_title('Zoom')
ax[1].set_ylim(22, 28)
ax[1].set_xlim(2, 7)
ax[1].axline((5, 25), slope=pendiente, color='red', label='pendiente?')
ax[1].hlines(y=4.99**2, xmin=0, xmax=4.99, linewidth=1, color='white', linestyles='dashed')
ax[1].hlines(y=25, xmin=0, xmax=5, linewidth=1, color='white', linestyles='dashed')
ax[1].vlines(x=4.99, ymin=0, ymax=4.99**2, linewidth=1, color='white', linestyles='dashed')
ax[1].vlines(x=5, ymin=0, ymax=25, linewidth=1, color='white', linestyles='dashed')
ax[1].legend()
plt.show()
Valor de la pendiente con una secante más pequeña: 9.990000000000023

En esencia, hemos minimizado las distancias entre
Como decía, idealmente queremos que la distancia
Pero ahora ya no hablamos de una pendiente exactamente, sino que la estamos alterando para conseguir un resultado distinto. A este nuevo concepto lo denominaremos «derivada»:
En la práctica también suele escribirse como
Aplicada a nuestro problema, podemos utilizarla así:
Programáticamente:
def derivada(f, x):
h = 0.001
return (f(x+h) - f(x)) / h
derivada(nolineal, 5)
10.001000000002591
Finalmente hemos descubierto que cuando
Ahora, podemos generalizar esta expresión bajo la fórmula
En suma,
Volviendo a lo nuestro, podemos concluir que, conceptualmente, la derivada —igual que la pendiente— mide la proporción o magnitud del cambio que una variable provoca en el resultado de una función. Digamos que la derivada mide la fuerza con la que una variable influye —en un determinado punto— en el resultado de una función.
Pongamos otro ejemplo: si los valores de la función nunca cambiaran, entonces su derivada sería
Supongamos que quiero medir la distancia que recorro en
tiempo = np.arange(0, 21, 1)
def f(t): return t*0
distancia = f(tiempo)
fig, ax = plt.subplots(figsize=(10, 7))
ax.plot(tiempo, distancia, marker='o', color='blue', label='recta de la función')
ax.set_facecolor('black')
ax.set_xlabel('Tiempo (segundos)')
ax.set_ylabel('Distancia (metros)')
ax.axline((tiempo[0], distancia[0]), slope=0, color='red', label='derivada / pendiente')
ax.legend()
plt.show()
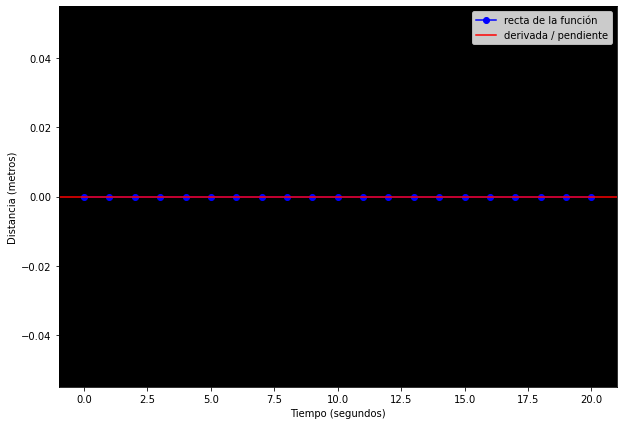
Veamos un último ejemplo, ahora con la función suma: mi variable
x = np.arange(0, 13, 2)
def f(x): return x+6
y = f(x)
z = {'Valores de x': x, 'Valores de y': y}
tabla = pd.DataFrame(data=z)
tabla = tabla.style.hide_index()
tabla
| Valores de x | Valores de y |
|---|---|
| 0 | 6 |
| 2 | 8 |
| 4 | 10 |
| 6 | 12 |
| 8 | 14 |
| 10 | 16 |
| 12 | 18 |
Ahora preguntémonos: ¿en qué proporción cambia
Esto tiene sentido porque la multiplicación aumenta nuestros valores con mayor velocidad y en diferente proporción que la suma: por ejemplo,
Grafiquemos nuestra nueva función de suma:
derivada = (y[2] - y[1]) / (x[2] - x[1])
fig, ax = plt.subplots(figsize=(10, 7))
ax.plot(x, y, marker='o', color='blue', label='recta de la función')
ax.set_facecolor('black')
ax.set_xlabel('Valores de x')
ax.set_ylabel('Valores de y')
ax.axline((x[1], y[1]), slope=derivada, color='red', label='derivada / pendiente')
ax.hlines(y=10, xmin=0, xmax=4, linewidth=1, color='white', linestyles='dashed')
ax.vlines(x=4, ymin=0, ymax=10, linewidth=1, color='white', linestyles='dashed')
ax.legend()
plt.show()
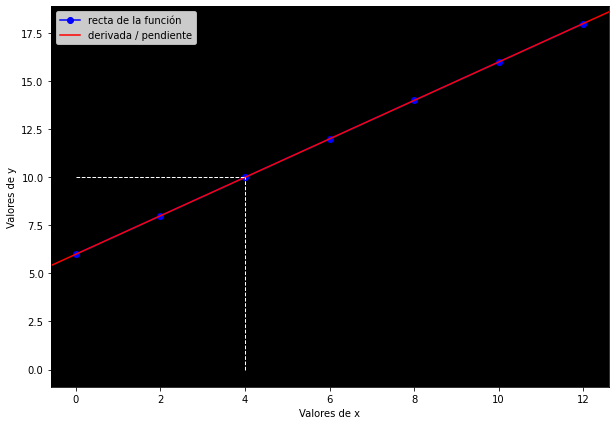
La inclinación de la recta es menor porque
Por otra parte, cuando cada valor de la función aumenta poco conforme hacemos más grande nuestra variable de entrada, entonces la derivada será pequeña y la inclinación será poca.
Pero ¿para qué sirve la derivada?#
Imaginemos que tenemos dos variables:
Supongamos que nuestro cambio aplicado será
Si recordamos la lección aprendida en las derivadas, se nos puede ocurrir utilizarlas para resolver este problema: dado que la derivada me dice el impacto que tiene una variable de entrada en la función, ¿será posible utilizarla para alterar el resultado de la función? Es decir, si la derivada me dice la magnitud del impacto que una varible tiene en el resultado, entonces debería poder utilizar esa información para influir en el resultado de manera más eficiente. Por ejemplo, si la derivada me indica que una variable influye positivamente en la función, pero yo quiero disminuirla, entonces sabré más o menos la magnitud en que debo disminuir esa variable, y así sucesivamente.
Pequegrad#
Para entender mejor la posible solución planteada, crearemos programáticamente la clase Numero, es decir, formularemos una estructura que nos permita definir, modificar y operar con números. De momento, cada Numero tendrá las siguientes propiedades: un valor, un par de valores previos para el caso de que el valor haya sido generado mediante una operación (por ejemplo, operación que generó dicho valor (en nuestro ejemplo, la multiplicación) y una etiqueta en caso de que queramos asociar nuestro valor a una variable. Por ahora, únicamente tendremos las operaciones de suma, multiplcación, resta y división:
class Numero:
def __init__(self, valor, _previos=(), _op='', etiqueta=''):
self.valor = valor
self._previos = set(_previos)
self._op = _op
self.etiqueta = etiqueta
def __add__(self, otro): # adición
otro = otro if isinstance(otro, Numero) else Numero(otro) # nos cercioramos de que el otro valor sea un Número
resultado = Numero(self.valor + otro.valor, (self, otro), '+')
return resultado
def __radd__(self, otro):
return self + otro
def __mul__(self, otro): # multiplicación
otro = otro if isinstance(otro, Numero) else Numero(otro)
resultado = Numero(self.valor * otro.valor, (self, otro), '*')
return resultado
def __rmul__(self, otro):
return self * otro
def __sub__(self, otro): # resta, substracción
return self + (-otro)
def __truediv__(self, otro): # división
return self * otro**-1 #dividir es lo mismo que multiplicar por el dividendo elevado a la menos 1
def __rtruediv__(self, otro):
return otro * self**-1
def __neg__(self): # volver negativo un número
return self * -1
def __repr__(self):
return f'Valor={self.valor}' # esta función determina cómo se representa nuestro número
Utilizaremos un problema más desafiante que una simple multiplicación:
# Definimos la función L con los siguientes números y operaciones:
a = Numero(-2.0, etiqueta='a')
b = Numero(3.0, etiqueta='b')
c = a*b; c.etiqueta = 'c' # definimos c, que es el resultado de multiplicar a y b
d = Numero(10.0, etiqueta='d')
e = c + d; e.etiqueta = 'e'
f = Numero(-3.0); f.etiqueta = 'f'
L = f * e; L.etiqueta= 'L'
print(f'Ejemplo: Valor de c: {c} | Valores previos: {c._previos} | Operación realizada para generar c: {c._op}')
Ejemplo: Valor de c: Valor=-6.0 | Valores previos: {Valor=3.0, Valor=-2.0} | Operación realizada para generar c: *
También crearemos una función para graficar nuestras operaciones:
from graphviz import Digraph
def rastreo(origen):
# construye un conjunto de todos los nodos en un gráfico
nodos, lineas = set(), set()
def construir(v):
if v not in nodos:
nodos.add(v)
for parte in v._previos:
lineas.add((parte, v))
construir(parte)
construir(origen)
return nodos, lineas
def graficar(origen):
grafica = Digraph(format='svg', graph_attr={'rankdir': 'LR'}) # left to right, izquierda a derecha
nodos, lineas = rastreo(origen)
for n in nodos:
uid = str(id(n))
# por cada valor en la gráfica, crea un nodo rectangular ('record') para él
grafica.node(name=uid, label='{ %s | valor %.4f}' % (n.etiqueta, n.valor), shape='record')
if n._op:
# si el valor es resultado de una operación, crea un nodo para la operación
grafica.node(name = uid + n._op, label = n._op)
# conecta los nodos
grafica.edge(uid + n._op, uid)
for n1, n2 in lineas:
# conecta n1 al nodo operación de n2
grafica.edge(str(id(n1)), str(id(n2)) + n2._op)
return grafica
Finalmente, visualizamos la función[2]. El problema a resolver consiste en influir en los valores de la función
graficar(L)

Como decíamos, intuitivamente creemos que la derivada puede ayudarnos: con la derivada sabemos qué impacto tiene cada variable en el resultado final
En principio, la derivada de
def derivada():
h = 0.000001
# Función original
a = Numero(-2.0, etiqueta='a')
b = Numero(3.0, etiqueta='b')
c = a*b; c.etiqueta = 'c'
d = Numero(10.0, etiqueta='d')
e = c + d; e.etiqueta = 'e'
f = Numero(-3.0); f.etiqueta = 'f'
L1 = f * e; L.etiqueta= 'L1'
# Función con incremento h
a = Numero(-2.0, etiqueta='a')
b = Numero(3.0, etiqueta='b')
c = a*b; c.etiqueta = 'c'
d = Numero(10.0, etiqueta='d')
e = c + d; e.etiqueta = 'e'
e.valor += h # aumento de h para obtener la derivada de L con respecto a e
f = Numero(-3.0); f.etiqueta = 'f'
L2 = f * e; L.etiqueta= 'L2'
print((L2 - L1) / h) # fórmula de la derivada
derivada()
Valor=-2.9999999995311555
La derivada de la función
Quizá también sea una buena oportunidad para demostrar analíticamente lo que venimos diciendo. Utilizando nuestra fórmula matemática, tenemos que:
Y aunque la notación aparente complejidad, en realidad solo estamos sumando, multiplicando, restando y dividiendo.
Ahora que ya tenemos esta información, queremos continuar al nodo anterior: las derivadas con respecto a
La regla de la cadena: propagación hacia atrás#
Tomemos prestada la analogía de George Simmons: si una bicicleta es dos veces más rápida que una persona corriendo, y un automóvil cuatro veces más rápido que una bicicleta, entonces el automóvil es
De igual forma, si queremos saber la influencia que
Ahora, para obtener la derivada de
def deriv_e(c, d):
return (((c+0.00001)+d) - (c+d)) / 0.00001
deriv_e(-6, 10)
0.9999999999621422
En efecto, el resultado es aproximadamente
Y ahora que ya tenemos ambas derivadas parciales, podemos multiplicarlas siguiendo la regla de la cadena:
Donde
Comprobémoslo programáticamente:
def derivada():
h = 0.000001
# Función original
a = Numero(-2.0, etiqueta='a')
b = Numero(3.0, etiqueta='b')
c = a*b; c.etiqueta = 'c'
d = Numero(10.0, etiqueta='d')
e = c + d; e.etiqueta = 'e'
f = Numero(-3.0); f.etiqueta = 'f'
L1 = f * e; L.etiqueta= 'L1'
# Función con incremento h
a = Numero(-2.0, etiqueta='a')
b = Numero(3.0, etiqueta='b')
c = a*b; c.etiqueta = 'c'
c.valor += h # aumento de h para obtener la derivada de L con respecto a c
d = Numero(10.0, etiqueta='d')
e = c + d; e.etiqueta = 'e'
f = Numero(-3.0); f.etiqueta = 'f'
L2 = f * e; L.etiqueta= 'L2'
print((L2 - L1) / h) # fórmula de la derivada
derivada()
Valor=-2.9999999995311555
Finalmente, debemos hacer lo mismo para obtener las derivadas con respecto a
Ahora que ya tenemos estos valores, podemos optimizar nuestro código para contemplarlos y visualizarlos de mejor manera. Añadiremos también algunas funciones que después detallaremos. En la práctica, nadie calcula las derivadas manualmente como lo hicimos, puesto que sería una labor eterna; pero ya hemos aprendido los patrones para calcularlas, así que podemos implementarlos en nuestro código para que se calculen automáticamente:
import math
class Numero:
def __init__(self, valor, _previos=(), _op='', etiqueta=''):
self.valor = valor
self.grad = 0.0 # gradiente, comienza en 0
self._propagar = lambda: None # el valor predeterminado de la propagación hacia atrás es nulo
self._previos = set(_previos)
self._op = _op
self.etiqueta = etiqueta
def __add__(self, otro):
otro = otro if isinstance(otro, Numero) else Numero(otro)
resultado = Numero(self.valor + otro.valor, (self, otro), '+')
def _propagar():
self.grad += 1.0 * resultado.grad # la derivada de una suma es 1; después, se multiplica por la «derivada global»
otro.grad += 1.0 * resultado.grad
resultado._propagar = _propagar
return resultado
def __radd__(self, otro):
return self + otro
def __mul__(self, otro):
otro = otro if isinstance(otro, Numero) else Numero(otro)
resultado = Numero(self.valor * otro.valor, (self, otro), '*')
def _propagar():
self.grad += otro.valor * resultado.grad # la derivada de la multiplicación es igual al multiplicando por la derivada global
otro.grad += self.valor * resultado.grad
resultado._propagar = _propagar
return resultado
def __rmul__(self, otro):
return self * otro
def __pow__(self, otro): # potenciación
assert isinstance(otro, (int, float))
resultado = Numero(self.valor**otro, (self,), f'**{otro}')
def _propagar():
self.grad += otro * (self.valor ** (otro - 1)) * resultado.grad # recordemos la fórmula: yx**y-1
resultado._propagar = _propagar
return resultado
def __sub__(self, otro):
return self + (-otro)
def __rsub__(self, otro):
return otro + (-self)
def __neg__(self):
return self * -1
def __truediv__(self, otro):
return self * otro**-1
def __rtruediv__(self, otro):
return otro * self**-1
def ReLU(self):
resultado = Numero((0 if self.valor < 0 else self.valor), (self,), 'ReLU')
def _propagar():
self.grad += (1 if resultado.valor > 0 else 0) * resultado.grad # la derivada es 1 si x > 0, 0 si x < 0
resultado._propagar = _propagar
return resultado
def tanh(self): # tangente hiperbólica
t = (math.exp(2*self.valor) - 1) / (math.exp(2*self.valor) + 1)
resultado = Numero(t, (self,), 'tanh')
def _propagar():
self.grad += (1 - t**2) * resultado.grad # según la fórmula 1-tanh**2x
resultado._propagar = _propagar
return resultado
def sigmoide(self):
s = 1/(1 + math.exp(self.valor))
resultado = Numero(s, (self,), 'sigmoide')
def _propagar():
self.grad += (s * (1 - s)) * resultado.grad # la derviada es s(x)(1-s(x))
resultado._propagar = _propagar
return resultado
def exp(self): # exponenciación
resultado = Numero(math.exp(self.valor), (self,), 'exp')
def _propagar():
self.grad += self.valor * resultado.grad
resultado._propagar = _propagar
return resultado
def log(self): # logaritmo natural
resultado = Numero(math.log(self.valor), (self,), 'log')
def _propagar():
self.grad += 1/self.valor * resultado.grad
resultado._propagar = _propagar
return resultado
def propagar(self):
# ordenamiento topológico
topo = []
visitados = set()
def construir_topo(v):
if v not in visitados:
visitados.add(v)
for previo in v._previos:
construir_topo(previo)
topo.append(v)
construir_topo(self)
self.grad = 1 # asignamos la derivada del valor final con respecto a sí mismo: 1
for nodo in reversed(topo): # comenzamos desde adelante hacia atrás
nodo._propagar()
def __repr__(self):
return f'Valor={self.valor}'
from graphviz import Digraph
def rastreo(origen):
nodos, lineas = set(), set()
def construir(v):
if v not in nodos:
nodos.add(v)
for parte in v._previos:
lineas.add((parte, v))
construir(parte)
construir(origen)
return nodos, lineas
def graficar(origen):
grafica = Digraph(format='svg', graph_attr={'rankdir': 'LR'})
nodos, lineas = rastreo(origen)
for n in nodos:
uid = str(id(n))
grafica.node(name=uid, label='{ %s | valor %.4f | grad %.4f}' % (n.etiqueta, n.valor, n.grad), shape='record')
if n._op:
grafica.node(name = uid + n._op, label = n._op)
grafica.edge(uid + n._op, uid)
for n1, n2 in lineas:
grafica.edge(str(id(n1)), str(id(n2)) + n2._op)
return grafica
a = Numero(-2.0, etiqueta='a')
b = Numero(3.0, etiqueta='b')
c = a*b; c.etiqueta = 'c'
d = Numero(10.0, etiqueta='d')
e = c + d; e.etiqueta = 'e'
f = Numero(-3.0); f.etiqueta = 'f'
L = f * e; L.etiqueta= 'L'
graficar(L)

Ahora obtendremos las derivadas, pero programática en vez de manualmente:
L.propagar()
graficar(L)

Bien. Ahora pongamos en práctica nuestra intuición: dado que el gradiente (o derivada global, o la colección de derivadas parciales de
Las siguientes imágenes ilustran con flechas azules la dirección del gradiente, y en blanco y negro a los valores de la función (el negro indica los valores más altos). Como digo, el gradiente indica la dirección en la que la función aumenta su valor:

Solo hace falta un detalle: al emplear esta estrategia, debemos ser cuidadosos de no excedernos en el aumento del resultado, puesto que queremos llegar a
na = a + 0.1 * a.grad # nuevo valor de a: su derivada multiplicada por 0.1 + el valor anterior de a
a = Numero(na.valor, etiqueta='a') # asignamos el nuevo valor a la variable
b = Numero(3.0, etiqueta='b')
c = a*b; c.etiqueta = 'c'
d = Numero(10.0, etiqueta='d')
e = c + d; e.etiqueta = 'e'
f = Numero(-3.0); f.etiqueta = 'f'
L = f * e; L.etiqueta= 'L'
L.propagar()
graficar(L)

Bien, parece que nuestro método funciona. Sin embargo, comprobamos que quizá nuestra fuerza es elevada, puesto que disminuyó mucho el resultado. Probablemente tengamos un mejor resultado si hacemos esto con todas nuestras variables, pero con una fuerza más atenuada (
na = a + 0.01 * a.grad
nb = b + 0.01 * b.grad
nd = d + 0.01 * d.grad
nf = f + 0.01 * f.grad
a = Numero(na.valor, etiqueta='a')
b = Numero(nb.valor, etiqueta='b')
c = a*b; c.etiqueta = 'c'
d = Numero(nd.valor, etiqueta='d')
e = c + d; e.etiqueta = 'e'
f = Numero(nf.valor); f.etiqueta = 'f'
L = f * e; L.etiqueta= 'L'
L.propagar()
graficar(L)

Aunque no hayamos conseguido un resultado de exactamente 0, nos hemos aproximado significativamente con nuestro nuevo método programático. Pronto explotaremos el verdadero poder detrás de esta nueva herramienta nuestra, aunque desde ya podamos proclamar —con Françoise Hardy— ¡voilà! Esta es la esencia del aprendizaje en una red neuronal.
Perceptrón multicapa#
Anteriormente, construimos una especie de neurona; sin embargo, el poder de una red neuronal consiste en que tiene millones de neuronas, todas optimizando sus valores para darnos el resultado que deseamos (en nuestro ejemplo:
A continuación, construiremos una red neuronal llamada «perceptrón multicapa» (Multilayer Perceptron o MLP en inglés) que nos permitirá resolver problemas prácticos. Como ejemplo, la entrenaremos para que identifique sarcasmo en reseñas de películas.
Para detectar sarcasmo en las reseñas que los usuarios dan sobre una película, podríamos tomar como base dos variables: el sentimiento (con valores del
Genial, me encanta cuando veo una película de terror con la típica trama de siempre. Calificación:
En este caso, el sentimiento es positivo (utiliza expresiones como «genial», «me encanta»), pero la reseña es negativa, de manera que podemos establecer una relación de proporcionalidad inversa entre ambas variables para detectar el sarcasmo: si la calificación es baja pero el sentimiento «alto», entonces hay sarcasmo (es decir, sarcasmo
#entradas
sentimiento = Numero(5.0, etiqueta='sentimiento')
calificacion = Numero(5.0, etiqueta='calificacion')
# pesos (weights)
w1 = Numero(-3.0, etiqueta='w1')
w2 = Numero(1.0, etiqueta='w2')
# sesgo (bias)
b = Numero(12, etiqueta='b')
# x1*w1 + x2*w2 + b
x1w1 = sentimiento*w1; x1w1.etiqueta='x1w1'
x2w2 = calificacion*w2; x2w2.etiqueta='x2w2'
sumatoria = x1w1 + x2w2; sumatoria.etiqueta='s'
n = sumatoria + b; n.etiqueta='n'
# activación
sarcasmo = n.tanh(); sarcasmo.etiqueta= 'sarcasmo'
sarcasmo.propagar()
graficar(sarcasmo)

Por el momento, nuestros valores son aleatorios y todo funciona mal. La calificación y el sentimiento que asignamos son
Primero, crearemos la clase Neurona para crear una estructura como la anterior. Al pasar nuestras variables por la Neurona, obtendremos un peso y un sesgo por cada una. Hecho esto, realizaremos operaciones con el peso, el sesgo y las entradas para transformar las entradas y, con ello, obtengamos al final el resultado deseado. Por ejemplo: si mis entradas son
Para obtener como resultado una probabilidad de sarcasmo del
import random
class Neurona:
def __init__(self, nentradas):
self.peso = [Numero(random.uniform(-1,1)) for i in range(nentradas)] # cada entrada tendrá un peso, que será un número aleatorio
self.sesgo = Numero(random.uniform(-1,1)) # un sesgo con valor aleatorio del -1 al 1
def __call__(self, x):
# peso * x + sesgo
activacion = sum((peso_i*x_i for peso_i, x_i in zip(self.peso, x)), self.sesgo) #multiplicamos, sumamos
resultado = activacion.tanh() # aplicamos la función tangente hiperbólica
return resultado
def parametros(self):
return self.peso + [self.sesgo]
#entradas
sentimiento = Numero(5.0, etiqueta='sentimiento')
calificacion = Numero(5.0, etiqueta='calificacion')
N = Neurona(2) # creamos una neurona
neuron = N([sentimiento, calificacion]) # damos a las variables como valores de entrada
neuron.propagar()
graficar(neuron)

Nuestros pesos y sesgos tienen valores aleatorios, de manera que esto sigue sin funcionar. Para optimizarlos apropiadamente, será mejor crear una arquitectura más robusta. Entendámonos: será difícil que encontremos un par de pesos tales que, multiplicados por nuestras dos entradas, reflejen apropiadamente el sarcasmo como queremos. Si tenemos más pesos, probablemente sea más fácil encontrar una combinación de números que arroje los resultados que queremos.
Para ello, crearemos una red neuronal. Lo único que nos falta es una forma de conectar varias neuronas entre sí, así podremos tener más pesos y sesgos que entrenar, lo cual se traduce en mejor desempeño.
Construiremos, pues, una «capa», que no es más que una forma programática de definir cuántas neuronas queremos para nuestras entradas, es decir, de generar una serie de neuronas; y finalmente conectaremos todo con un «perceptrón multicapa», que consiste en unir varias capas entre sí:
class Capa: # Layer
def __init__(self, nentradas, nsalidas):
self.neuronas = [Neurona(nentradas) for _ in range(nsalidas)]
def __call__(self, x):
resultado = [n(x) for n in self.neuronas]
return resultado[0] if len(resultado) == 1 else resultado
def parametros(self):
return [parametro for n in self.neuronas for parametro in n.parametros()]
class MLP: # Perceptrón multicapa
def __init__(self, nentrada, nsalidas):
tamaño = [nentrada] + nsalidas
self.capas = [Capa(tamaño[i], tamaño[i+1]) for i in range(len(nsalidas))]
def __call__(self, x):
for capa in self.capas:
x = capa(x)
return x
def parametros(self):
return [parametro for capa in self.capas for parametro in capa.parametros()]
Veamos una capa como ejemplo:
x = [1.0, 2.0, 3.0]
C = Capa(4, 1)
graficar(C(x))

Ahora veamos una red neuronal de la especie perceptrón multicapa:
x = [3.0, 2.0]
RN = MLP(4, [4, 4, 1])
graficar(RN(x))

Como vemos, únicamente estamos interconectando y creando más neuronas para que nuestro modelo tenga más potencia. Al mismo tiempo, vemos que una neurona interconecta las entradas entre sí a través de pesos y sesgos. Los pesos y sesgos, además de realizar operaciones diferenciables (es decir, que podemos derivar), nos ayudarán a ir midiendo la relevancia de cada entrada para, con base en el gradiente, ajustarse en proporción a dicha relevancia. De igual forma, los pesos y sesgos articularán el patrón de números que en este caso necesitamos para convertir cada combinación de entradas en una probabilidad de sarcasmo.
Ahora manos a la obra. Daremos a nuestro modelo cuatro entradas de entrenamiento (es decir, serán ejemplos para que la red neuronal aprenda): cada entrada tendrá el sentimiento y la calificación asignada, así como el valor de sarcasmo objetivo que deseamos:
entradas = [
[5.0, 5.0], # no sarcasmo
[5.0, 1.0,], # sarcasmo
[5.0, 2.0], # sarcasmo
[4.0, 5.0], # no sarcasmo
]
objetivos = [0.0, 1.0, 1.0, 0.0]
predicciones = [RN(x) for x in entradas]
predicciones
[Valor=0.3669362864564352,
Valor=0.06860246608538911,
Valor=0.3213103120229461,
Valor=0.3486194765977301]
Nuestras predicciones de sarcasmo fueron generadas con valores aleatorios, de manera que todas son erróneas. Ahora, debemos cuantificar qué tan alejadas están de su objetivo. Para ello, crearemos una función que mida la diferencia entre el objetivo y la predicción. Se trata de una simple resta, pero la elevaremos al cuadrado para obtener solo números positivos:
fn_perdida = [(pred - obj)**2 for pred, obj in zip(predicciones, objetivos)] #Mean Squared Error
fn_perdida
[Valor=0.13464223831843908,
Valor=0.8675013661822187,
Valor=0.46061969256639074,
Valor=0.1215355394632753]
Ahora, sumaremos los valores entre sí para obtener una sola cifra que nos permita cuantificar el desempeño general de nuestro modelo:
perdida = sum(fn_perdida)
perdida
Valor=1.5842988365303239
Luego, con base en la función de pérdida, haremos propagación hacia atrás: obtendremos los gradientes y, con ello, sabremos en qué dirección modificar nuestros pesos y sesgos para que la pérdida (o el error, o la distancia) sea
perdida.propagar()
graficar(perdida)

Esto ya luce mucho más como una red neuronal. Calcular manualmente todos los gradientes sería engorroso; pero la programación nos permite apalancarnos de los algoritmos, las matemáticas y las computadoras para explotar su potencial a gran escala.
Echemos un vistazo a nuestros parámetros (o sea, pesos y sesgos):
RN.parametros()
[Valor=0.26185647542075774,
Valor=-0.3897146431515013,
Valor=-0.042130217416122884,
Valor=0.716233520043825,
Valor=0.34035823314645985,
Valor=-0.38262186196333725,
Valor=0.016423299964780647,
Valor=-0.9183633316805504,
Valor=-0.5763110561373717,
Valor=0.019367922187966347,
Valor=0.12454783116525658,
Valor=0.6707556894941378,
Valor=0.834698024121612,
Valor=0.254042516410647,
Valor=-0.6730022053225764,
Valor=-0.8928621154187195,
Valor=0.7161297325281775,
Valor=0.09323426117937772,
Valor=0.7985780052593621,
Valor=-0.9972537117506883,
Valor=-0.0037082550344191834,
Valor=0.7422268948402582,
Valor=-0.7202178129671104,
Valor=-0.49309665896689103,
Valor=0.48794442651441616,
Valor=0.6622683039011021,
Valor=-0.9732767794233275,
Valor=0.7338007914809526,
Valor=-0.12433377269499779,
Valor=0.6796016177396522,
Valor=-0.2252461785794555,
Valor=-0.25469641100646667,
Valor=0.25222074387643856,
Valor=-0.636707051411459,
Valor=-0.08679161950639269,
Valor=0.26446327705831196,
Valor=0.21401883070848138,
Valor=0.3809439666539909,
Valor=-0.010349121884670964,
Valor=-0.47937169114088274,
Valor=-0.7563496531288552,
Valor=-0.690391901144549,
Valor=0.9515007803442808,
Valor=0.6590463877459278,
Valor=0.21212402329507696]
Aunque para nosotros puedan no significar nada, lo cierto es que con base en el gradiente, nuestro modelo aprenderá a configurarlos de tal manera que representen un patrón cuya función será arrojar el resultado que nosotros queremos.
Ahora, dado que nuestra función de pérdida es positiva, queremos disminuirla. Si los gradientes nos indican la dirección en la que podemos aumentar el resultado de una función, entonces en este caso queremos ir en dirección opuesta al gradiente, pues eso tendría como resultado una disminución del resultado de la función. Para ello, sumaremos valor a las variables en el sentido inverso al gradiente (o, visto de otra forma, les restaremos valor según nos indique el gradiente).
Para optimizar de mejor manera, haremos este mismo paso
for k in range(30):
# paso hacia delante
preds = [RN(x) for x in entradas]
perdida = sum([(pred - obj)**2 for pred, obj in zip(preds, objetivos)])
# propagación hacia atrás, Stochastic Gradient Descent
for p in RN.parametros():
p.grad = 0.0
perdida.propagar()
# actualizar
for p in RN.parametros():
p.valor += -0.07 * p.grad
print(k, perdida.valor)
0 1.5842988365303239
1 1.2529558664951095
2 0.587216087017959
3 0.4191023147078547
4 0.5752410954325351
5 1.1191852453113773
6 1.784366523080085
7 1.652128457073363
8 1.224657076741451
9 0.26771058028648226
10 0.41855267707767796
11 0.707877061951523
12 0.15361704203665727
13 0.12954214337233716
14 0.12316318950192393
15 0.12964905806896287
16 0.1261090038316882
17 0.1336944727568814
18 0.11078544833502019
19 0.102441253791397
20 0.08312278356688153
21 0.0723339169867922
22 0.06107490601393822
23 0.053290880990198526
24 0.04659821460517871
25 0.04138965501323435
26 0.03716069258091919
27 0.03363478739730862
28 0.030798690241934046
29 0.02833061619126015
Al parecer, nuestra función de pérdida disminuyó casi a cero. Comprobemos que nuestras predicciones ahora sean más similares a nuestros objetivos:
preds
[Valor=0.1016585786227638,
Valor=0.9171470012496584,
Valor=0.8984522443847082,
Valor=0.02862836899357634]
objetivos
[0.0, 1.0, 1.0, 0.0]
En efecto, nuestro modelo ya es mucho más apto ahora que antes para detectar sarcasmo. ¿Qué tal si hacemos un test con una nueva calificación? El sentimiento será de
test = [5.0, 1.5]
prediccion = RN(test)
prediccion
Valor=0.9022088768249822
Nuestra red neuronal considera que existe un